The 3+1 AI Coworker Stack: Why I Cut Copilot and Hired Cursor as a Temp
0 · Four AI Coworkers, Workflow Restructured
After that one tweet on 4/19 about running 4 AI terminals at once went viral, people kept asking: how do you actually set this up?
I promised to write it down. Ten days later, my workflow changed again:
- Copilot got cut. I used it for a while, then realized Claude Code Tab and Cursor Tab were overlapping in the exact same scenarios. It occupied an SKU but delivered marginal value—ROI didn't add up, so I canceled.
- Cursor came in, but as a temp. Starting 5/1, I'm burning through $10K in free credits running background daemons. Expires 5/31. After that, I'll decide whether to renew based on actual results.
So this can't be "the 4-tool setup guide." The real state is 3 full-timers + 1 temp worker.
Here's the judgment I didn't unpack in the original tweet: AI coworkers aren't a fixed SKU lineup. They're a dynamic combo you adjust based on current opportunities. Whether a tool survives depends on one question: Does it own a unique use case? If two tools overlap and the ROI doesn't work, you cut it—no matter how polished it is.
Below, 4 sections walk through the real workflow. Each covers: positioning / config essentials / collaboration patterns / when to use. Section 5 goes solo on why I cut Copilot—that reasoning matters more than my tool picks. Section 6 is a collaboration diagram. Section 7 is the one-liner summary.
Who this is for: Independent developers and content creators already using 1-2 AI coding tools and wondering how to orchestrate a multi-model workflow.
Who this isn't for: Absolute beginners with zero AI tool experience (go find an intro guide first); pure product managers or non-coders (this setup is overfit to what I do).
1 · Claude Code · The Manager
Positioning
The manager for all my other AI coworkers. Handles conversation, judgment calls, coordination, code review, complex planning, skill dispatch, and all Chinese-language writing (X posts / long-form / docs).
It's not the one that writes the most code. It's the one that decides what everyone else should write.
Config Essentials
Entry: claude CLI (Max subscription: $100/month baseline, $200/month for long-running projects worth the investment).
Three P0 config pieces:
~/.claude/CLAUDE.md= global behavior SSOT. All delivery standards, work preferences, collaboration rules, and SSOT routing live here.~/.claude/memory/active-tasks/T*.jsonper-task files (aggregate viewactive-tasks.jsonauto-rebuilds) = cross-session task handoff panel. Every task must haveid/title/owner; owner is onlyclaudeorcodex.- Per-project
MEMORY.md+patterns.md= project-level lessons learned + reusable patterns across projects. When corrected, updatepatterns.mdimmediately—don't wait for session-end.
Write discipline is a P0 red line: missing those three required fields in active-tasks schema = downstream /next / /today can't find task names = cross-model handoff breaks.
Skills load on-demand: user-level ~/.claude/skills/ fires on keyword triggers. leo-style for tweets, article-pipeline for long-form, content-verify for fact-checking, humanizer to strip AI-speak—all custom skills.
Collaboration Mode
- Upstream: Me (conversation) + Codex review reports (multi-model chess) + Cursor daemon output (handoff relay)
- Downstream: Codex runs review / Cursor daemon chews backlog / I make final calls and publish
- Typical flow: I pitch a need → Claude drafts a plan + SOP → if it touches strategy code, I route to Codex review → once Codex stamps ✅ reviewed, we move forward
When to Use / When Not to Use
✅ Use: 3+ files changing, architecture tradeoffs, writing ≥1500-word pieces, debugging stuck for 30min with no leads, cross-session complex hand-offs, public-facing content (tweets / Articles).
❌ Don't use: Adding one type signature, renaming three variables, installing a dependency, quick command lookup (overkill and wastes Max tier).
2 · Codex · The Auditor + Code Reviewer
Positioning
Independent reviewer of strategy, financial, and data-foundation code. Not here to write the most. Here to prevent Claude's main thread from groupthink.
Two words matter: independent. The Codex prompt must contain independent success criteria, never copied from Claude's framework. Codex evaluates from scratch; it's not incremental review on top of Claude's conclusions. I learned this the hard way—when Codex mirrors Claude's reasoning, the dual-review layer falls apart.
It can also run headless automation, but I mostly use it synchronously for review, not as a dispatcher.
Config Essentials
Entry: codex CLI, shares ~/.claude/memory/active-tasks/ per-task JSON write-back whitelist with Claude.
Default reasoning effort settings (gets the tradeoff right):
| Task Type | Effort | Command |
|---|---|---|
| Strategy / Financials / PnL / Market-making / Wallet signing | xhigh | codex -c model_reasoning_effort=xhigh |
| Data pipelines / Backtesting / Data processing | high | same as above, high |
| General review / Refactors | high | same as above |
| Docs / Config | medium | same as above, medium |
Medium effort cuts corners on strategy code; extreme effort costs tokens that feel cheap next to debug time. Learned this through trial-and-error.
After each write, run node ~/.claude/scripts/sync-active-tasks.mjs to rebuild the aggregate view, or active-tasks.json lags and downstream routing breaks.
Collaboration Mode
- Upstream: Claude packages a plan and asks for independent judgment
- Downstream: Stamp ✅ reviewed or list issues → back to Claude's main thread for triage
- Typical flow: Claude finishes strategy code → "let Codex take a look" → Codex rigor=xhigh catches 5 real bugs → Claude fixes → one more pass
When to Use / When Not to Use
✅ Use: Any strategy plan / code / data-foundation execution plan / financial operations / PnL calculation logic. Before shipping anything involving money, Codex reviews it.
❌ Don't use: Pure docs / comments / log formats / ≤5 lines of config (sledgehammer for a nail). Open-ended exploration tasks ("find what's worth improving") also don't work—it gives you a shallow laundry list.
Subscription: ChatGPT Plus $20/month includes Codex CLI basics; Pro $200/month unlocks full capacity.
3 · Grok · The Intelligence Officer
Positioning
The intel officer—real-time information retrieval. X post searches, single-post reads, thread continuations, cross-platform search, finding Quote source material, verifying whether a claim broke this week or months ago. Grok owns all of that.
It doesn't write code, make judgment calls, or participate in decisions. It's purely the "what's the current chatter / does this information have a source" person.
Config Essentials
Entry: Local Grok Bridge at 127.0.0.1:19998, auto-starts via launchd with Safari session state injected. Call it like:
rtk proxy curl -X POST http://127.0.0.1:19998/chat \
-d '{"q":"<your question>","mode":"deepsearch"}'Why not opencli grok ask: that tool frequently returns NO RESPONSE—unreliable. Grok Bridge borrows Safari's authenticated session and routes through the front-end API, much more stable.
Companion retrieval tools:
- opencli twitter — single post / thread grab (default)
- xreach — thread self-reply catchall (when the author uses 🧵 threads and opencli misses them)
- mcp__twitter — user profiles / search / KOL followers (fallback only; use opencli/xreach first)
URL routing SSOT lives in ~/.claude/docs/url-routing.md—a one-page map of which tool handles which platform, plus fallback order.
Collaboration Mode
- Upstream: Claude gets a URL / someone asks "what's Karpathy saying lately" / need to find Quote source material
- Downstream: Grok returns the raw text / data to Claude for judgment
- Typical flow: "What's the reaction to that new Karpathy post" → Grok Bridge grabs post + reads replies → Claude drafts Quote → I edit
When to Use / When Not to Use
✅ Use: Search trending topics / find Quote raw material / analyze a single post / grab threads / cross-platform search (YouTube / Reddit / GitHub trending) / verify a data point / confirm whether a quote has a real source.
❌ Don't use: Write code / make architecture calls / long reasoning chains (not what it's built for).
Subscription: Bundled into X Premium+ ($16-22/month), not a separate SKU.
4 · Cursor · The Temp Worker (Expires 5/31)
Positioning
Brought on in May as a temporary hire. Starting 5/1, burning through $10K in free credits for background daemons. Expires 5/31. Renewal depends on ROI math.
Role boundaries are tight:
- Doesn't enter decision-making — all daemon output funnels to main-thread Opus, nothing publishes directly
- Doesn't touch strategy / finance / wallet code — hardcoded as a red line in daemon prompt
- Doesn't fake skill execution — daemon can't actually invoke
humanizer/content-verify/ call nano-banana for images / apply SSOT footers. Those belong to the main thread
What it can do: batch work with hard acceptance criteria + solid guardrails. Bulk spec doc generation / SOP writing / Python scripts + mocks + README sections, long-form first drafts for merging, skeleton outlines.
Config Essentials
Entry: cursor-agent SDK; launchd runs cursor-sdk-loop (com.leo.cursor-sdk-loop) 24/7.
Work mode: daemon reads ~/Projects/_inventory/cursor-product-backlog.md in reverse for ^- [ ] checkbox tasks, locks one, runs it, marks done as [x-sdk].
Core prompt template (three steps for content-class tasks):
- Merge (consolidate multiple sections + hook writing)
- Structure (4-6 anchor points)
- Inline CSS HTML skeleton (no real images embedded)
Explicitly declare what the daemon can't do in the prompt header—don't let it claim work it never did. I learned this the hard way: daemon would stamp "humanizer pass ✅ + verify checklist done" when it never actually ran either, basically lying. Now it's forbidden.
Hard red lines (baked into prompt):
- ❌ Don't touch
prediction-trader/prediction-farmerany.ts/.py/.mjs - ❌ Don't write API keys / cookies / tokens / wallet private keys
- ❌ Don't call external finance APIs
- ❌ Don't post tweets / open GitHub PRs / edit vault SSOT tables
- ❌ Don't claim skill execution happened if it didn't
Collaboration Mode
- Upstream: Me (main thread Opus) writes backlog tasks + routes to the right pipeline (content class A / script class B / doc class C)
- Downstream: Output lands in vault or
_inventory/tools/→ main thread Opus picks it up (must do so for A-class / spot-check B/C) - Typical flow: I write 6 spec tasks → daemon burns through them 5-10min each → produces 6 vault docs → I spot-check 1-2 with Sonnet → anything ⭐⭐⭐ up goes straight to archive
When to Use / When Not to Use
✅ Use: Bulk specs / SOPs / research docs (C-class); scripts + mocks + README (B-class); long-form skeleton + merge (A-class first draft, but don't expect final polish).
❌ Don't use: Strategy code / financial code / anything needing independent judgment / anything requiring fact-checking / images / final publishing.
Cost: $0 (free trial burn). If renewal happens, likely Pro $20/month or Ultra $200/month.
5 · The Fired Coworker: Why I Canceled Copilot
This section matters more than which tools I kept.
I used GitHub Copilot Pro at $19/month for VS Code ghost text completions + gh copilot suggest in the terminal. After a while, two problems emerged:
Problem one: Scenario overlap with other tools was too high.
- IDE completions: Cursor's Tab already does this better (agent mode even handles multi-file edits)
- Terminal command hints: Just asking Claude Code is more reliable than
gh copilot suggest
Problem two: Occupied an SKU but delivered marginal value.
- Cost: $19/month isn't expensive
- Time cost: Switching tools (VS Code Copilot ↔ Cursor ↔ Claude CLI ↔ Codex) burns more time than the few seconds of completions save
After I killed it, I didn't miss anything. That itself is the answer: if canceling a tool doesn't hurt, it wasn't pulling its weight in the first place.
One lesson: Don't stack AI tools by feature count. Stack by unique ownership. If two tools have 70% overlap, keep one.
6 · Collaboration Diagram: How 3 Full-Timers + 1 Temp Connect
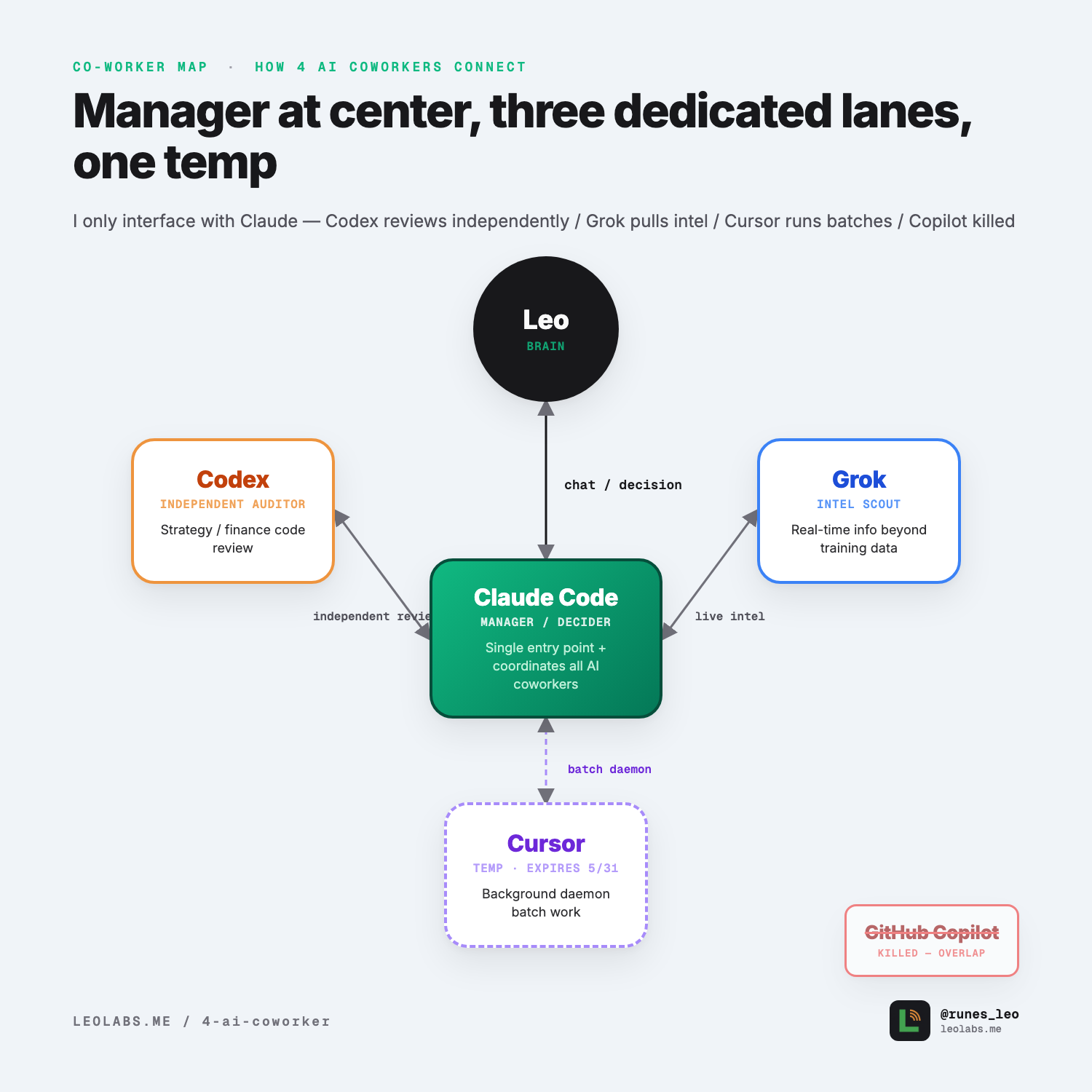
Notice the Cursor line is dashed—temp worker, expires 5/31. The other three are solid, long-term fixtures.
Three-Axis Division Breakdown
| Dimension | Claude Code Manager | Codex Auditor | Grok Intelligence Officer | Cursor Temp Worker |
|---|---|---|---|---|
| Reasoning Depth | ★★★★★ | ★★★★★ | ★★ | ★★★ |
| Context Window | ★★★★★ | ★★★★ | ★★★ | ★★★★ |
| Interaction Latency | ★★ | ★ (sync review) | ★★★★ | ★ (headless daemon) |
| Unique Use Case | Main decisions / Content writing / Skill dispatch | Strategy / Finance independent review | Real-time intel grab | Background batch work (trial) |
| Monthly Cost | $100 (5x) / $200 (20x) | $20 (Plus) / $200 (Pro) | Bundled in X Premium+ ($16-22) | $0 (trial) / $20-200 if renewed |
| Employment Status | Long-term | Long-term | Long-term | Expires 5/31—renewal TBD |
7 · Takeaway: AI Coworkers Are Dynamic, Not Fixed
Three key points:
- Three full-timers (Claude / Codex / Grok) lock in long-term because each owns unique territory: main decisions / independent review / real-time intel. Zero overlap.
- Temps arrive by opportunity, leave by ROI. Cursor's here because of $10K free credits; 5/31 decides if it stays. Copilot got cut because overlap was too high and unique territory too thin.
- Tool count ≠ output. To decide if an AI coworker should stay, ask one question: "If I cancel this, do I hit a wall?" Yes → keep it. No wall → kill it. This rule beats any config guide.
I'm planning to post an update 5/31—either "4 full-timers" if Cursor converts, or "back to 3" if it doesn't. The result comes straight: no hedging.